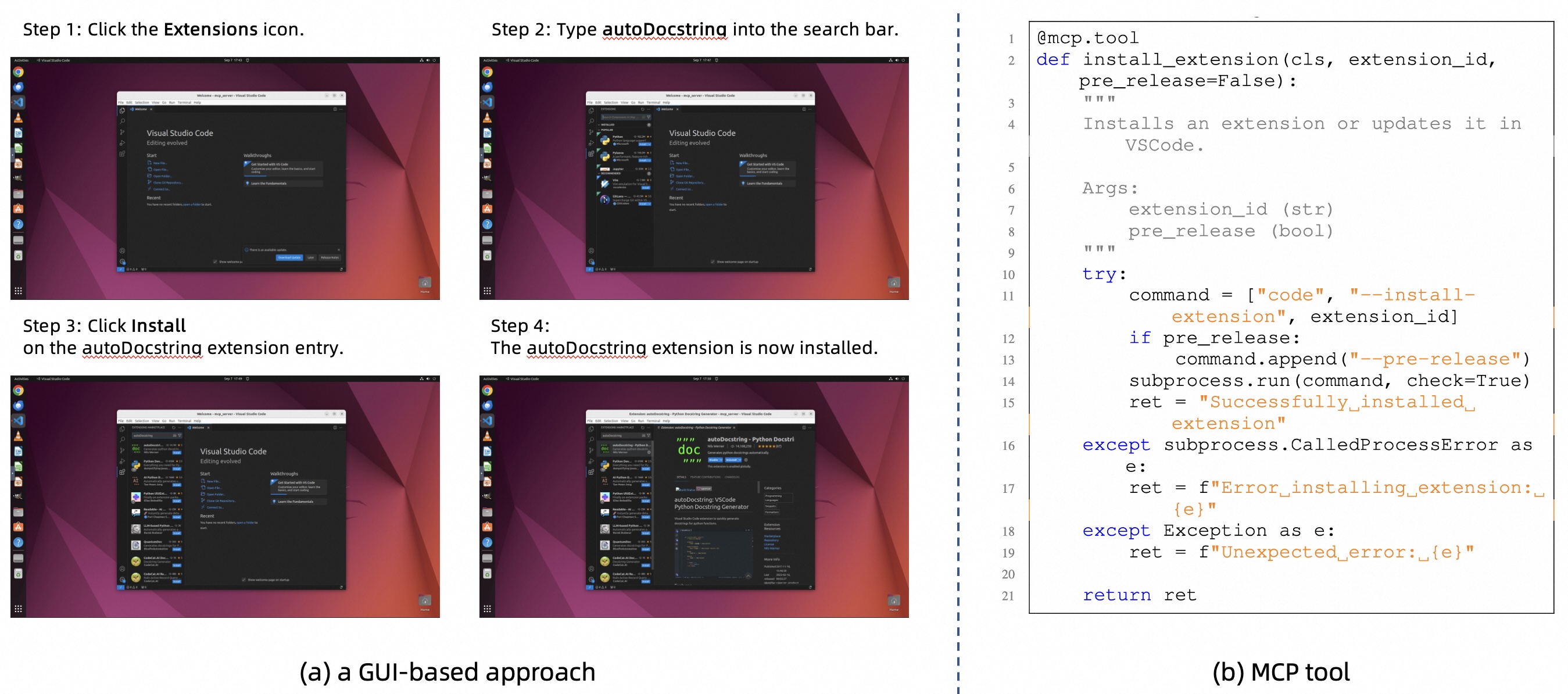
Figure 1: Task execution via GUI vs MCP Tool
Authors: Hongrui Jia1,2,†, Jitong Liao2,†, Xi Zhang2,†, Haiyang Xu2,*, Tianbao Xie2, Chaoya Jiang1, Ming Yan2,*, Si Liu3, Wei Ye1,*, Fei Huang2
Affiliations: 1 Peking University · 2 Tongyi Lab, Alibaba Group · 3 Beijing Zhongguancun Academy
With advances in decision-making and reasoning capabilities, multimodal agents have shown strong potential in computer application scenarios. Past evaluations mainly assessed GUI interaction skills, while tool invocation abilities enabled by the Model Context Protocol (MCP) have been largely overlooked. We present OSWorld-MCP, the first comprehensive and fair benchmark for assessing computer-use agents’ tool invocation, GUI operation, and decision-making abilities in a real-world environment.
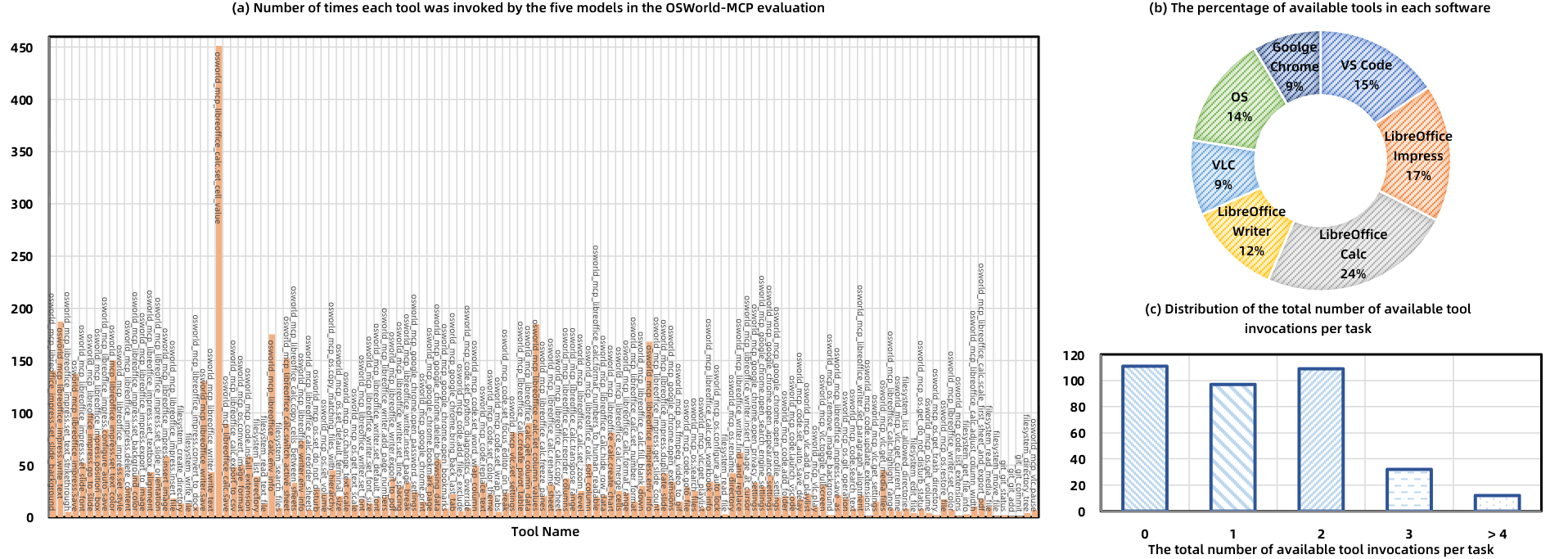
We adopt state-of-the-art LLM and VLM from open-source representatives such as
Agent-S, Qwen
and closed-source ones from GPT, Gemini, and Claude families on OSWorld-MCP,
as LLM and VLM agent baselines.
Acc, TIR, and ACS denote the three evaluation metrics:
Task Accuracy, Tool Invocation Rate, and Average Completion Steps.
Unified Prompt: To facilitate comparison of performance differences across models, we standardized our evaluation using the GUI-Owl agent configuration. This may lead to some performance fluctuations for certain models under their original OSWorld configuration.
Specific Prompt: Each model adopts its own unique configuration for OSWorld-MCP evaluation.
We are actively updating the benchmark with new LLMs, VLMs and methods. Please submit the invocation method and evaluation scripts.
Pull requests welcomed!
For more information, contact:
jiahongrui@stu.pku.edu.cn,
shuofeng.xhy@alibaba-inc.com,
zx443053@alibaba-inc.com.
| Rank | Model | Details | Acc | TIR | ACS |
|---|---|---|---|---|---|
|
Type: Agentic framework
Max Steps: 15
Runs: 3 Prompt: unified prompt
|
42.1 | 30.0 | 10.0 | ||
|
Type: General model
Max Steps: 15
Runs: 3 Prompt: unified prompt
| 36.1 | 27.4 | 10.5 | ||
|
Type: General model
Max Steps: 15
Runs: 3 Prompt: unified prompt
| 32.8 | 21.5 | 10.0 | ||
|
Type: General model
Max Steps: 15
Runs: 3 Prompt: unified prompt
| 30.7 | 21.0 | 10.1 | ||
|
Type: General model
Max Steps: 15
Runs: 3 Prompt: unified prompt
| 17.6 | 11.6 | 11.9 | ||
|
Type: General model
Max Steps: 15
Runs: 3 Prompt: unified prompt
| 17.4 | 12.2 | 11.6 | ||
|
Type: General model
Max Steps: 15
Runs: 3 Prompt: unified prompt
| 14.5 | 10.1 | 14.0 | ||
|
Type: Agentic framework
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 49.5 | 35.3 | 17.0 | ||
|
Type: General model
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 45.0 | 33.3 | 20.0 | ||
|
Type: General model
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 39.5 | 26.1 | 18.6 | ||
|
Type: General model
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 38.2 | 25.1 | 22.3 | ||
|
Type: General model
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 25.7 | 16.8 | 31.0 | ||
|
Type: General model
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 24.1 | 16.0 | 33.0 | ||
|
Type: General model
Max Steps: 50
Runs: 3 Prompt: unified prompt
| 15.6 | 9.3 | 39.0 |
Click headers to sort, use buttons to filter results.